Multimodal Spatial Domains
Conceptually, it is easy to extend SpatialLeiden to more than modality. As clustering is done on multiple graphs, the number of graphs can simply be extended. Instead of using 2 graphs (one for neighbors in physical space and one for the neighbors in the feature latent space, e.g., gene expression) we use \(n+1\) graphs where \(n\) is the number of modalities (see Figure below).

To demonstrate how to cluster multiple modalities jointly we will use the simulated data from Long et al. 2024, which can be downloaded from Zenodo.
from pathlib import Path
import anndata as ad
import numpy as np
import pandas as pd
import scanpy as sc
import squidpy as sq
from mudata import MuData
from spatialleiden import spatialleiden_multimodal
# settings
simulation = Path("../path/to/data") / "Dataset13_Simulation1"
seed = 42 # random seed for reproducibility
Load & prepare data
We start by loading the data and only keeping the relevant information.
modalities = {}
# load modalities
for file in simulation.glob("*.h5ad"):
modality = file.stem.split("_")[1]
adata = ad.read_h5ad(file)
# only keep the raw counts
adata.X = adata.layers["counts"]
del adata.layers, adata.uns, adata.varm
modalities[modality] = adata
From the two modalities we will construct a mudata.MuData object, which is basically the multimodal extension of AnnData. We remove some duplicated information from the two modalities and construct the groundtruth labels.
# prepare MuData
mdata = MuData(modalities)
mdata.var_names_make_unique()
mdata.obs["groundtruth"] = pd.Categorical(
mdata.mod["RNA"].obsm["spfac"].astype(int) @ np.array([1, 2, 3, 4])
)
mdata.obsm["spatial"] = mdata["RNA"].obsm["spatial"]
for _, mod in mdata.mod.items():
del mod.obsm
print(mdata)
MuData object with n_obs × n_vars = 1296 × 1100
obs: 'groundtruth'
obsm: 'spatial'
2 modalities
ADT: 1296 x 100
RNA: 1296 x 1000
/home/jovyan/spacehack-v3/projects/7_SpatialLeiden_multiX/SpatialLeiden2_Study/conda_envs/vignette/lib/python3.12/site-packages/mudata/_core/mudata.py:963: UserWarning: Cannot join columns with the same name because var_names are intersecting.
warnings.warn(
/home/jovyan/spacehack-v3/projects/7_SpatialLeiden_multiX/SpatialLeiden2_Study/conda_envs/vignette/lib/python3.12/site-packages/mudata/_core/mudata.py:1629: UserWarning: Modality names will be prepended to var_names since there are identical var_names in different modalities.
warnings.warn(
Next, we will do some basic processing steps for the two modalities. This includes library-size normalization, log-transformation, and PCA.
# process modalities
for name, adata in mdata.mod.items():
n_pcs = 30 if name == "RNA" else 10
sc.pp.normalize_total(adata)
sc.pp.log1p(adata)
sc.pp.scale(adata)
sc.pp.pca(adata, n_comps=n_pcs, random_state=seed)
Clustering with multimodal SpatialLeiden
To cluster the data with SpatialLeiden we will need one neighbors graph per modality. We will generate kNN graphs for each modality based on the PCA.
# generate kNN graph per modality
for adata in mdata.mod.values():
sc.pp.neighbors(adata, use_rep="X_pca", random_state=seed)
As the data originates from a regular grid we can generate our spatial neighbors graph accordingly. For more information on how to generate a suitable spatial graph have a look here.
# spatial neighbors
sq.gr.spatial_neighbors(mdata, coord_type="grid", n_neighs=8)
Now that we have our 3 graphs ready (the spatial graph in physical space, and the two kNN graphs in the feature latent space of the two modalities) we can proceed to cluster them using spatialleiden.spatialleiden_multimodal().
The resolution can be uniform across all layers or set individually per layer.
Layer weights control each graphs influence on the clustering result (and therefore how much each modality or spatial neighborhood will contribute).
Additional options include specifying directed or undirected graphs and whether to use edge weights.
# cluster with spatialleiden
spatialleiden_multimodal(
mdata,
resolution=0.5,
layer_weights={"ADT": 1, "RNA": 1.5, "spatial": 2.5},
random_state=seed,
)
To compare, we first look at the two single modalities. Unfortunately, the data is not available, however, we can retrieve the groundtruth from the publication. As we can see, each individual modality only contains a subset of the clusters (geometric structures visible in the image).
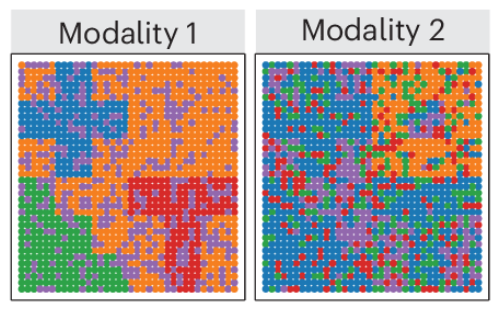
Now, after clustering the modalities jointly with spatialleiden we can see that the 5 distinct clusters have been correctly retrieved meaning that the information from both modalities has been succesfully integrated.
import matplotlib.pyplot as plt
import seaborn as sns
scatter_kwargs = dict(x="x", y="y", s=25, lw=0, legend=False)
def remove_tick_and_label(ax):
ax.set(xticklabels=[], yticklabels=[], xlabel=None, ylabel=None)
ax.tick_params(left=False, bottom=False)
labels = mdata.obs[["groundtruth", "spatialleiden"]]
labels[["x", "y"]] = mdata.obsm["spatial"]
fig, axs = plt.subplots(ncols=2, sharex=True, sharey=True, figsize=(6, 3))
for label, ax in zip(["groundtruth", "spatialleiden"], axs):
_ = sns.scatterplot(data=labels, hue=label, ax=ax, **scatter_kwargs)
ax.set(title=label, aspect=1)
remove_tick_and_label(ax)
fig.tight_layout()